9. La UI de Jaeger
9. La UI de Jaeger
Las trazas no sirven si no las podés leer. La UI de Jaeger es la herramienta principal para diagnosticar incidentes, y dominarla cambia cuánto tiempo tardás en encontrar la causa raíz de un problema.
Capturas tomadas en una instancia real con dos servicios: jaeger-all-in-one (el propio Jaeger) y unisimon-backend (un servicio de ejemplo).
Vista 1 — Search
Punto de entrada. Buscás trazas filtrando por servicio, operación, tags, duración y rango temporal.
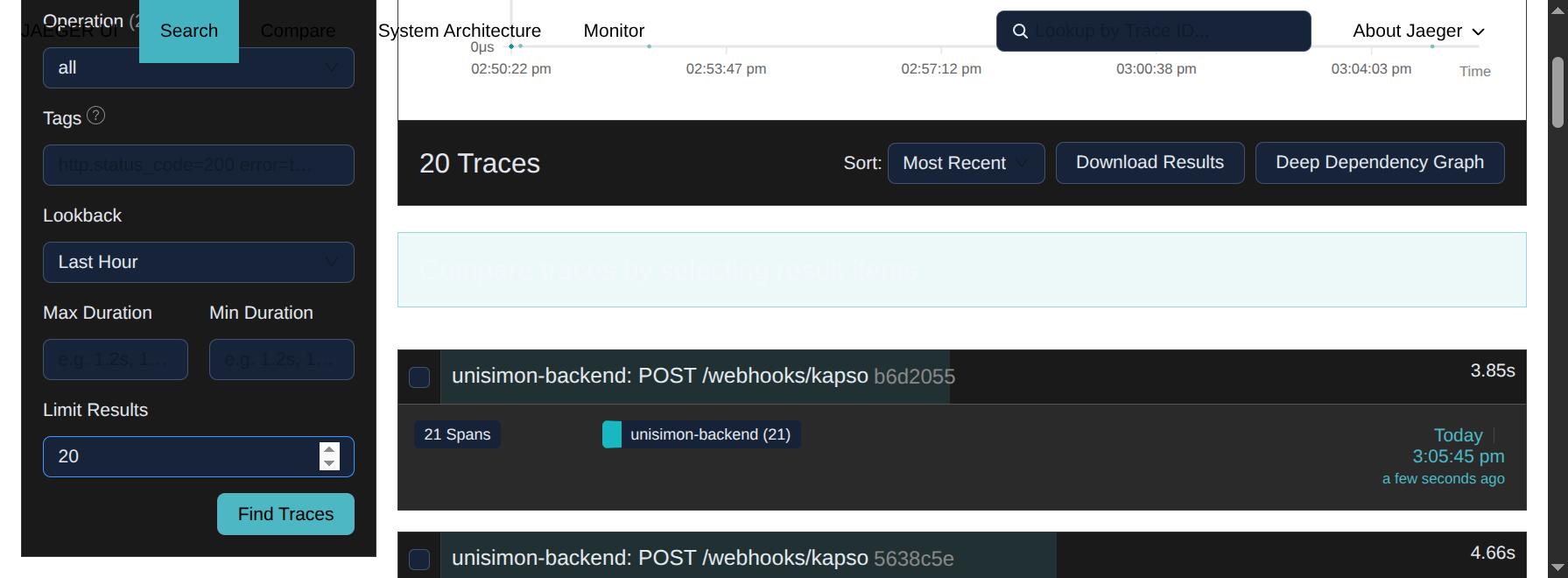
Filtros principales:
| Campo | Para qué |
|---|---|
| Service | Selecciona el servicio. Es el atributo service.name de tus apps |
| Operation | Filtra por operación específica del servicio (ej. POST /webhooks/kapso) |
| Tags | Filtros por atributos: http.status_code=500, error=true, user.tier=premium |
| Lookback | Rango temporal: última hora, día, custom |
| Min/Max Duration | Trazas más rápidas o más lentas que un umbral |
| Limit Results | Cantidad de resultados |
El gráfico de scatter
En la captura, arriba de la lista hay un gráfico tiempo (x) vs duración (y) donde cada punto es una traza. Sirve para detectar:
- Outliers: puntos sueltos arriba — esas son las trazas raras y lentas.
- Patrones temporales: una banda de puntos lentos a las 14:50 indica un problema correlacionado.
- Distribución: si hay dos clusters claros, probablemente tenés dos modos de operación distintos (cache hit vs miss, por ejemplo).
Tags útiles
| Tag query | Para qué |
|---|---|
error=true | Solo trazas con algún span en error |
http.status_code=500 | Errores HTTP server |
http.status_code>=400 | Errores client + server |
db.system=postgresql user.id=4221 | Trazas que tocaron Postgres para un usuario específico |
Los tags soportan AND implícito entre claves. Para OR usás múltiples búsquedas o el endpoint de la API directo.
Vista 2 — Trace Timeline
El corazón del debugging. Mostrá una traza completa con todos sus spans en un Gantt.
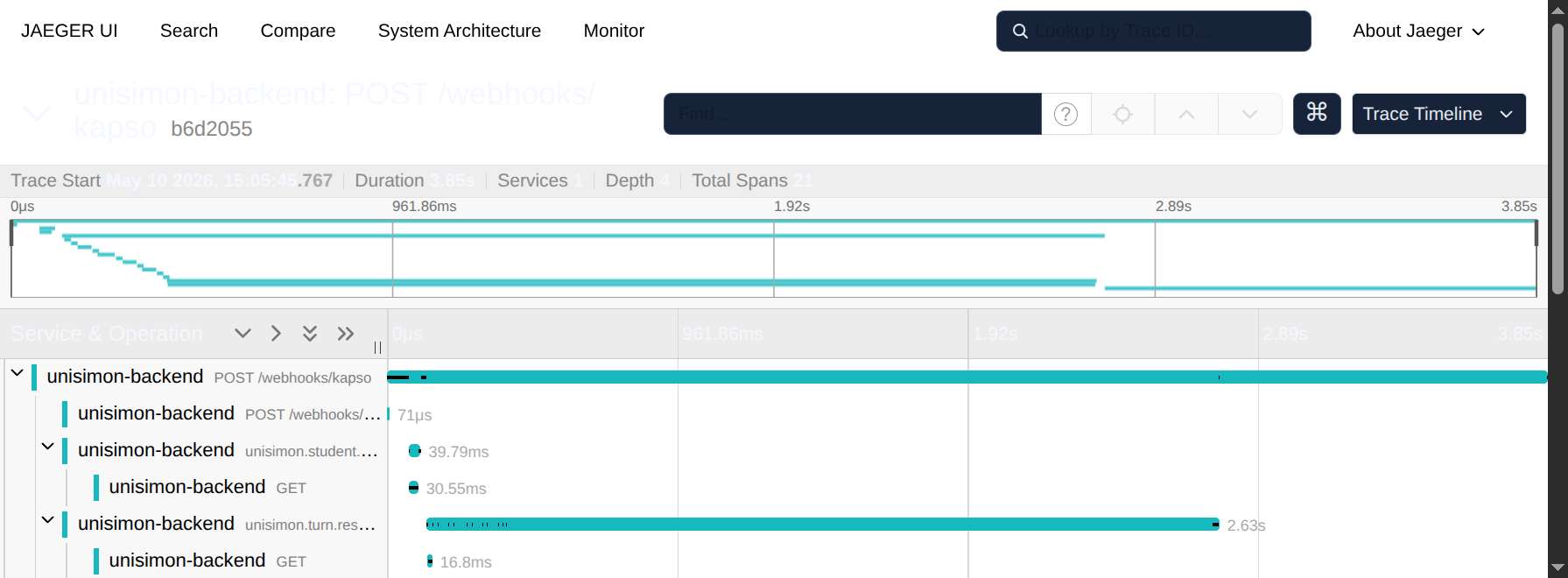
En esta captura:
- Trace de 3.85s (
POST /webhooks/kapso) con 21 spans. - Profundidad 4 — la jerarquía llega a 4 niveles.
- 1 servicio involucrado.
- En el Gantt podés ver visualmente cuál span se llevó la mayor porción del tiempo.
Cómo leer el timeline
- El primer span (root) es el que recibió la request.
- Cada barra representa un span — su largo es la duración, su posición horizontal es cuándo empezó.
- Indentación = jerarquía. Span hijo aparece debajo y a la derecha del padre.
- Color depende del servicio. En sistemas multi-servicio cada color es un servicio.
Patrones visuales típicos
█████████████████████ ← root span (toda la duración)
█████ ← op 1 secuencial
████ ← op 2 (espera a 1)
████████ ← op 3 (espera a 2)
█████ ← op 4 (lo que se está debuggeando — el cuello)vs
█████████████████████
█████ █████ █████ ← varias ops paralelasvs
█████████████████████
█████ ← gap antes de la op 2 — algo bloqueó
█████El “gap” es información valiosa: si entre dos spans hay tiempo sin otro span explicándolo, alguien (típicamente el thread principal) estuvo trabajando sin instrumentar. Acá necesitás más spans manuales.
Búsqueda dentro del trace
Arriba de la lista de spans hay un buscador. Escribí error o el nombre de una operación y los spans matching se resaltan. Esencial en trazas con cientos de spans.
Vista 3 — Span Detail
Click en cualquier span y se expande con todo su detalle.
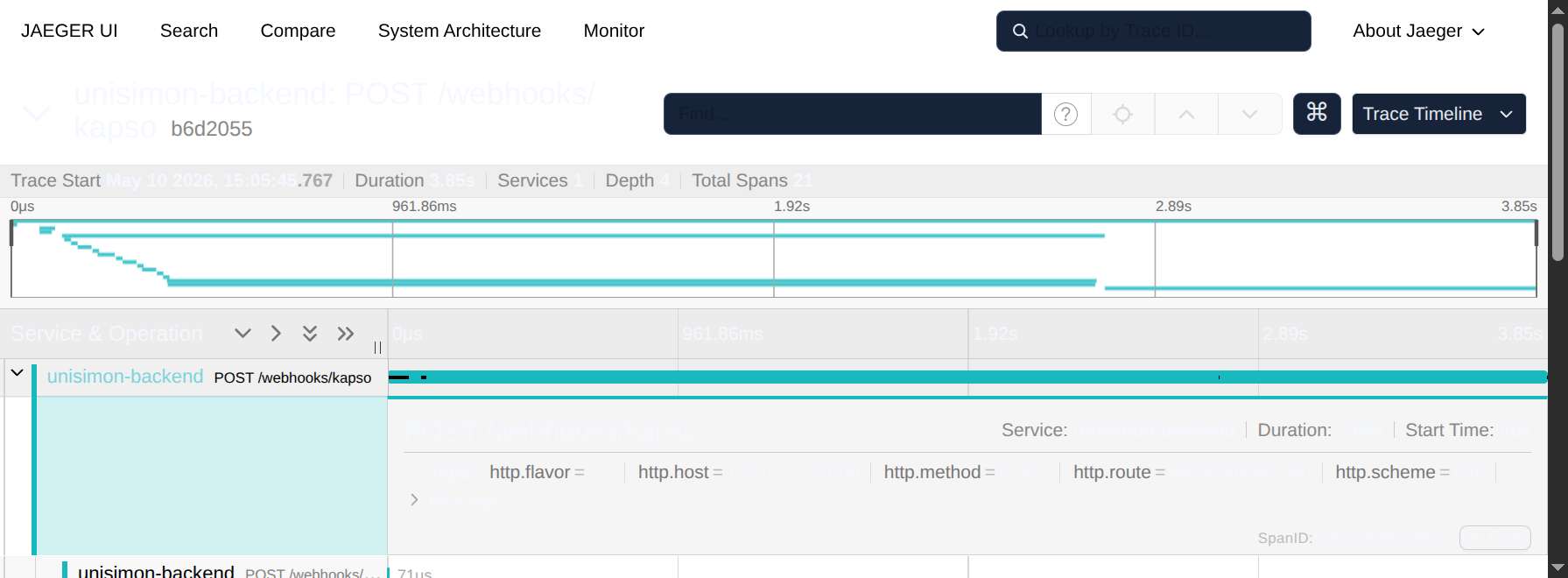
Información disponible:
| Sección | Contenido |
|---|---|
| Tags / Attributes | Todos los atributos del span: HTTP method, status, route, etc. |
| Process | Atributos del recurso: service.name, host, k8s metadata |
| Logs / Events | Eventos puntuales con timestamp |
| References | Parent y links a otros spans |
Triada habitual de búsqueda
Para un span lento, tres lugares para mirar:
- Tags
db.statement/http.url: ¿qué query exacta o qué URL llamó? - Tags de error: ¿status code? ¿exception type?
- Logs / Events: ¿hubo eventos internos al span que expliquen el tiempo (cache miss, retry)?
Vista alternativa: Trace Graph
En lugar del Gantt, podés ver la traza como un grafo de servicios o como un flame graph. Tabs arriba a la derecha del timeline:
- Trace Timeline (default): Gantt
- Trace Graph: nodo por servicio con flujo de calls
- Trace Statistics: tabla con cuántos spans por servicio, latencia agregada
- Trace Spans Table: lista plana ordenable
Vista 4 — System Architecture
Grafo dirigido de las dependencias entre servicios, derivado automáticamente de las trazas.
Cómo se calcula:
- Por cada span con
kind=CLIENTque llama a un servicio conkind=SERVER, se suma 1 al edge de “A llama a B”. - El espesor del edge representa el volumen.
Casos de uso:
- Onboarding de gente nueva al equipo: ven el sistema completo en una imagen.
- Detección de dependencias inesperadas: “¿el servicio de notificaciones llama directamente a la base de datos de orders?” (smell de acoplamiento).
- Análisis pre-cambio: antes de tocar un servicio, ver quién lo consume.
Limitación: en backends como Cassandra el grafo se calcula con un job batch (Spark), no en vivo. En Elasticsearch puede ser en vivo pero más caro.
Vista 5 — Monitor (SPM)
Service Performance Monitoring: RED metrics (Rate, Errors, Duration) derivadas de las trazas.
Tres métricas estándar por servicio:
- Request rate (req/s)
- Error rate (% errors)
- Duration (p50, p95, p99)
Ventaja sobre métricas tradicionales: si un endpoint particular está lento, click → buscás trazas lentas de ese endpoint en ese rango de tiempo. Te lleva del agregado a la traza individual.
Requisito: Jaeger tiene que estar configurado con un backend de métricas (Prometheus normalmente) y un componente que genere métricas a partir de los spans (spanmetrics processor). Cubrimos la setup en el capítulo 13.
Vista 6 — Compare
Permite comparar dos trazas lado a lado y ver diferencias estructurales.
Cuándo usarlo:
- Misma operación lenta y rápida → “¿qué hace distinto la rápida?”
- Antes y después de un deploy → “¿qué cambió en la estructura del trace?”
- Versión sana vs versión con bug → “¿qué span apareció / desapareció?”
Acceso: desde la vista de Search, seleccionás dos trazas con los checkboxes y click en “Compare Traces”.
Lookup by Trace ID
Arriba a la derecha hay un input de “Lookup by Trace ID…”. Pegás un trace ID y vas directo al timeline.
Caso de uso clave: tu sistema de logs incluye trace_id en cada log estructurado. Cuando un usuario reporta un problema con un timestamp, encontrás el log → tomás el trace_id → lookup → tenés el trace completo.
Ejemplo de log con trace_id:
{
"level": "error",
"message": "payment failed",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user_id": "9374"
}Esa correlación logs ↔ trazas es el superpoder que el observability stack te da. Sin trace_id en logs, no estás capitalizando la inversión.
Atajos de teclado útiles
| Tecla | Acción (en timeline) |
|---|---|
f | Foco en el buscador de spans |
g | Ir al inicio del timeline |
G | Ir al final del timeline |
+ / - | Zoom in / out |
Consejo final
La UI no es donde investigás todo. Es donde terminás la investigación.
Flujo eficiente:
- Métricas dicen “hay un problema”: p99 subió.
- Logs o alertas dan un trace_id sospechoso.
- Jaeger UI te muestra exactamente qué span y por qué.
Si solo abrís Jaeger reactivamente cuando ya pasó algo, estás dejando valor en la mesa. Mirá el Monitor (SPM) o construí dashboards de Grafana con las métricas de tu collector — esos son los que disparan la investigación.
¿Qué viene?
Sabés generar trazas, propagarlas, samplearlas y leerlas. Falta el problema operacional grande: dónde guardarlas a escala. En el próximo capítulo comparamos los backends de storage soportados.